整合營銷服務(wù)商
電腦端+手機(jī)端+微信端=數(shù)據(jù)同步管理
免費(fèi)咨詢熱線:

電腦端+手機(jī)端+微信端=數(shù)據(jù)同步管理
免費(fèi)咨詢熱線:

天天在用錢

作者 |朱順意
出品 | 腳本之家(ID:jb51net)
也許有的人在數(shù)字營銷行業(yè)已經(jīng)很長時(shí)間,天天和各種各樣的名詞打交道,但一不留神還是容易混淆一些名詞,甚至很多人連java和都混為一談。一起來看看容易混淆的都有哪些:
01
h5和html5
平時(shí)我們常說的h5是指移動(dòng)端網(wǎng)頁(包括pad和phone),因?yàn)榫W(wǎng)頁涉及到html5的代碼規(guī)范,所以大家習(xí)慣了叫h5。但實(shí)際上h5與html5并不是完全一個(gè)意思,你會(huì)聽到人家說“這個(gè)h5挺炫”,而不會(huì)聽到“這個(gè)html5挺炫”。
準(zhǔn)確來說,html5是html的一種規(guī)范,文檔類型聲明、標(biāo)簽語義化、功能比以往的html更便捷更強(qiáng)大;h5是通常指移動(dòng)端網(wǎng)頁,例如手機(jī)上的活動(dòng)頁、專題頁。
h5還有另一種含義,就是h5標(biāo)題標(biāo)簽。在SEO工作中,h1標(biāo)題標(biāo)簽包裹的關(guān)鍵詞會(huì)被強(qiáng)化SEO效果(僅次于title標(biāo)簽),h2-h6次之。

02
前端就是離用戶視覺最近的一面,例如樣式(顏色/圖片/大小/寬高/布局)、交互(下拉/隱藏/漸變/動(dòng)畫),常用技術(shù)包括html/css/;后端就是服務(wù)器數(shù)據(jù)傳輸、網(wǎng)絡(luò)安全,通常用戶接觸不到,常用技術(shù)包括PHP/Python/Java等等。
拿一個(gè)新聞網(wǎng)站來舉例,前端負(fù)責(zé)頁面的布局、文字大小顏色等等,后端負(fù)責(zé)把數(shù)據(jù)庫的新聞內(nèi)容、新聞時(shí)間等按一定順序在頁面呈現(xiàn),所以前后端實(shí)際上是互相合作的關(guān)系。近年來流行的“前后端分離”,并不是指前后端不再合作,而是通過API來解耦前端和后端。
在數(shù)字營銷也會(huì)有人把廣告監(jiān)測稱為前端,網(wǎng)站、小程序、APP監(jiān)測稱為后端,甚至有人把銷售稱為前端,運(yùn)營稱為后端。
03
自適應(yīng)和響應(yīng)式
乍一看這好像沒有什么區(qū)別,自適應(yīng)和響應(yīng)式都能讓頁面適應(yīng)不同的屏幕尺寸,不同的是,自適應(yīng)要先通過判斷當(dāng)前設(shè)備是PC、平板還是手機(jī),然后再去請求服務(wù)器給予不同的頁面模板,而響應(yīng)式是可以隨著當(dāng)前瀏覽器可視區(qū)域的大小而實(shí)時(shí)改變布局。
換句話來說,自適應(yīng)需要做PC、平板、手機(jī)這3種頁面模板,對(duì)應(yīng)的寬度分別是>=1200px(PC大屏幕)、>=992px(PC中等屏幕)、>=768px(平板)、而響應(yīng)式只需要做一個(gè)頁面模板,自由改變布局。
如果你還有疑問,打開以下網(wǎng)站調(diào)整瀏覽器的寬度,對(duì)比一下布局就明白了:
自適應(yīng):
響應(yīng)式:

04
動(dòng)態(tài)頁面和靜態(tài)頁面
這2者不能單純以頁面有無動(dòng)態(tài)效果(例如動(dòng)畫)來區(qū)分,而要看數(shù)據(jù)有沒有從服務(wù)器端查詢。也不能以網(wǎng)址有沒有包含“?”來區(qū)分動(dòng)靜態(tài)網(wǎng)頁,在數(shù)字營銷中“”表示用戶來源于百度,但并不代表這個(gè)頁面是動(dòng)態(tài)的。
常見動(dòng)態(tài)網(wǎng)頁的網(wǎng)址后綴常為.asp/.jsp/.php/.perl/.cgi,頁面內(nèi)容是通過后端語言(例如java)去請求服務(wù)器連接數(shù)據(jù)庫拿到的;靜態(tài)頁面的網(wǎng)址后綴常為.html/.htm/.xml/shtml,頁面內(nèi)容是固定寫在頁面上的。當(dāng)然動(dòng)態(tài)頁面也可以通過偽靜態(tài)以實(shí)現(xiàn)網(wǎng)址以.html等結(jié)尾。
所以,只通過瀏覽器查看源代碼,是不能判斷頁面為動(dòng)態(tài)還是靜態(tài)的。
05
第1方cookie和第3方cookie
這兩者本質(zhì)上沒有什么區(qū)別,都是cookie,為存放在本地的文本文件,所謂的第1方和第3方只是身份說明。cookie 有 domain 屬性,當(dāng) cookie 的 domain 與當(dāng)前地址欄的域名不同時(shí),這個(gè) cookie 為第3方 cookie,反之為第1方 cookie。
由于 domain 的不同,第1方 cookie 記錄的是用戶在指定站點(diǎn)的行為,第3方 cookie 記錄的是用戶在不同站點(diǎn)的行為。監(jiān)測工具為你的站點(diǎn)創(chuàng)建了第1方 cookie,這個(gè) cookie 的domain 屬于你的站點(diǎn),僅能用于記錄你站點(diǎn)的用戶行為,同時(shí)監(jiān)測工具也創(chuàng)建了第3方 cookie,這個(gè) cookie 的domain 屬于監(jiān)測工具,這個(gè) cookie 用于記錄所有部署了它的監(jiān)測代碼的站點(diǎn)數(shù)據(jù)。

關(guān)于這2者的詳細(xì)說明,我在另一篇文章《如何用Chrome讀懂網(wǎng)站監(jiān)測Cookie》有寫到。
06
openID和unionID
這2者在微信生態(tài)都用于標(biāo)識(shí)用戶,openid是用戶在某一應(yīng)用下的唯一標(biāo)識(shí),例如同一個(gè)用戶在A小程序和B小程序是2個(gè)不同的openid。然而,同一用戶在同一個(gè)微信開放平臺(tái)賬號(hào)下的不同應(yīng)用(移動(dòng)應(yīng)用、網(wǎng)站應(yīng)用、公眾號(hào)、小程序),unionid是相同的。
雖然有2個(gè)天然標(biāo)識(shí)用戶的ID,但在微信小程序監(jiān)測中,很多第3方工具會(huì)通過wx.以鍵值對(duì)的形式創(chuàng)建具有唯一性的用戶ID,這個(gè)ID會(huì)一直穩(wěn)定存在,除非用戶主動(dòng)刪除或因存儲(chǔ)空間原因被系統(tǒng)清理。
07
、MAC地址、IMEI、OAID
這幾種都是安卓設(shè)備ID。的獲取不需要用戶授權(quán),在Android 8.0及以上,由應(yīng)用簽名、用戶和設(shè)備三者的組合,而不直接為設(shè)備唯一標(biāo)識(shí);
MAC地址屬于硬件ID,具有唯一性,涉及用戶隱私;
IMEI為國際移動(dòng)設(shè)備識(shí)別碼,具備唯一性(當(dāng)然也要考慮雙卡雙待的情況)。在Android 6.0以上,IMEI的獲取需要用戶授權(quán),也可以通過撥打*#06#查詢。
由于IMEI已被認(rèn)定為用戶隱私的一部分,Android 10.0起將徹底禁止第三方應(yīng)用獲取設(shè)備的IMEI,從而中國信通院聯(lián)合國內(nèi)手機(jī)廠商共同推出新的設(shè)備識(shí)別字段 - OAID,OAID為匿名設(shè)備標(biāo)識(shí)符,用戶可以禁用、重置。

08
api和sdk
api是指一個(gè)功能或者一個(gè)函數(shù),我們把相關(guān)參數(shù)傳入,調(diào)用api然后由它返回?cái)?shù)據(jù)(返回的形式通常是json),例如使用谷歌天氣預(yù)報(bào)api時(shí),傳入城市id和日期等參數(shù),然后谷歌會(huì)返回天氣、溫度、濕度、舒適指數(shù)等信息。

SDK是一個(gè)或多個(gè)文件的組合(包括代碼文件也包括文檔),是一種工具包,下載之后可以嵌入你的網(wǎng)頁或移動(dòng)應(yīng)用,由sdk去調(diào)用api實(shí)現(xiàn)具體功能,例如嵌入第三方的廣告SDK接入聯(lián)盟廣告。所以說,SDK通常會(huì)包含很多不同的API。
09
維度和指標(biāo)
簡單來說,維度和指標(biāo)的關(guān)系是:以維度查看指標(biāo)。
維度是指數(shù)據(jù)的屬性、特征或范圍,例如城市、設(shè)備、瀏覽器、時(shí)間、廣告來源等等。當(dāng)1個(gè)維度后面關(guān)聯(lián)第2個(gè)維度時(shí),第2個(gè)維度被稱為次級(jí)維度,例如需要統(tǒng)計(jì)城市為北京、手機(jī)為蘋果的瀏覽量時(shí),手機(jī)為次級(jí)維度。
指標(biāo)是計(jì)算數(shù)值或者計(jì)算結(jié)果,例如瀏覽量、會(huì)話量、用戶數(shù)、訪問時(shí)長、跳出率、退出率等等。當(dāng)然也不能把所有數(shù)值都當(dāng)成指標(biāo),例如第1天簽到了100人,第2天簽到50人,那么第1天、第2天是維度,100人、50人才是指標(biāo)。
10
ecpm、cpm、ocpm
ecpm是指廣告每展現(xiàn)1千次,媒體所獲得的收入,這個(gè)指標(biāo)用于衡量媒體的廣告盈利能力;cpm指的是廣告每展現(xiàn)1千次,廣告主所付出的成本。看上去好像2個(gè)指標(biāo)是一樣,實(shí)際上如果一種廣告背后是cpc、cpt、cpm等幾種計(jì)費(fèi)方式,此時(shí)計(jì)算ecpm則需要進(jìn)行換算。

ocpm是在廣告投放中,一種以轉(zhuǎn)化為優(yōu)化目標(biāo)的展現(xiàn)出價(jià),也就是說按轉(zhuǎn)化出價(jià),計(jì)費(fèi)方式為展現(xiàn)計(jì)費(fèi)。同樣的道理,ocpc也是按轉(zhuǎn)化出價(jià),計(jì)費(fèi)方式為點(diǎn)擊計(jì)費(fèi)。無論是ocpm還是ocpc的投放方式,廣告展現(xiàn)勝出的能力還是要看ecpm,也就是要看1次轉(zhuǎn)化所花的錢換算成千次展現(xiàn)收入是多少。
也許你還聽說過ecpc,ecpc也是一種投放方式,有的人叫點(diǎn)擊出價(jià)系數(shù)控制,是指你設(shè)置一個(gè)出價(jià)系數(shù)區(qū)間,系統(tǒng)會(huì)根據(jù)流量轉(zhuǎn)化率動(dòng)態(tài)調(diào)整出價(jià),優(yōu)化轉(zhuǎn)化效果。
11
跳出率和退出率
跳出率(Bounce Rate)是落地頁指標(biāo),跳出率=跳出次數(shù)/訪問次數(shù)。跳出次數(shù)是指用戶來到網(wǎng)站,沒有任何交互就離開的訪問次數(shù)。至于是否有交互,要以監(jiān)測工具是否收到監(jiān)測請求為準(zhǔn),需要注意的是一般監(jiān)測工具的熱力圖請求不參與跳出率的計(jì)算。
退出率(Exit Rate)則是退出頁面(離開網(wǎng)站前瀏覽的最后1個(gè)頁面)的指標(biāo),退出率=退出次數(shù)/頁面瀏覽量。退出次數(shù)是指作為退出頁面的次數(shù),當(dāng)然如果用戶訪問的最后一個(gè)頁面還觸發(fā)了虛擬PV,那么此時(shí)退出頁面為虛擬PV頁面。
12
KOL和KOC
KOL(Key Opinion Leader)是關(guān)鍵意見領(lǐng)袖,指某個(gè)領(lǐng)域的專家、名人、明星,在相關(guān)用戶群體有較大影響力;KOC(Key Opinion )是關(guān)鍵意見消費(fèi)者,指通過自身試用推薦影響身邊消費(fèi)者的素人、愛好者。
KOC雖然知名度不高,但是離消費(fèi)者更近,與消費(fèi)者互動(dòng)效果也更強(qiáng)。KOC概念的產(chǎn)生,是由于隨著流量的稀缺,商家從花錢在大平臺(tái)買流量到利用熟人關(guān)系推介產(chǎn)品轉(zhuǎn)變,提高效果的同時(shí)也降低了營銷門檻。

13
無埋點(diǎn)/全埋點(diǎn)、可視化埋點(diǎn)、代碼埋點(diǎn)
無埋點(diǎn)也叫全埋點(diǎn),是指SDK部署到產(chǎn)品(網(wǎng)頁、小程序、APP)之后,將自動(dòng)監(jiān)聽用戶的各種行為,并且全部上報(bào)給監(jiān)測工具,隨后分析人員通過監(jiān)測工具的可視化面板將需要的數(shù)據(jù)按組件(按鈕、圖片、鏈接等等)進(jìn)行圈選。這種方式比較方便,但由于采集的數(shù)據(jù)實(shí)在太多,難免有丟包的情況,以及會(huì)存在明顯的數(shù)據(jù)冗余;
可視化埋點(diǎn)是先通過可視化面板將需要統(tǒng)計(jì)數(shù)據(jù)的組件進(jìn)行圈選,備注監(jiān)測信息,然后等待數(shù)據(jù)回傳,跟無埋點(diǎn)/全埋點(diǎn)的順序剛好相反。這種方式相對(duì)精確,但是有些交互難以通過圈選的方式來指定(例如下拉刷新);
代碼埋點(diǎn)則為根據(jù)統(tǒng)計(jì)目的,提前把監(jiān)測代碼交給開發(fā)人員配置到產(chǎn)品,代碼內(nèi)容一般包括觸發(fā)條件、事件維度、事件指標(biāo)等等,這種監(jiān)測方式比較準(zhǔn)確但是工作量也比較大。
簡言之,無埋點(diǎn)/全埋點(diǎn):全部上報(bào) -> 可視化圈選 -> 下載數(shù)據(jù);可視化埋點(diǎn):可視化圈選 -> 上報(bào)數(shù)據(jù) -> 下載數(shù)據(jù);代碼埋點(diǎn):配置代碼 -> 上報(bào)數(shù)據(jù) -> 下載數(shù)據(jù)。
機(jī)器學(xué)習(xí)基礎(chǔ)之《回歸與聚類算法(4)—邏輯回歸與二分類(分類算法)》
一、什么是邏輯回歸
1、邏輯回歸( )是機(jī)器學(xué)習(xí)中的一種分類模型,邏輯回歸是一種分類算法,雖然名字中帶有回歸,但是它與回歸之間有一定的聯(lián)系。由于算法的簡單和高效,在實(shí)際中應(yīng)用非常廣泛
2、叫回歸,但是它是一個(gè)分類算法
二、邏輯回歸的應(yīng)用場景
1、應(yīng)用場景
廣告點(diǎn)擊率:預(yù)測是否會(huì)被點(diǎn)擊
是否為垃圾郵件
是否患病
金融詐騙:是否為金融詐騙
虛假賬號(hào):是否為虛假賬號(hào)
均為二元問題
2、看到上面的例子,我們可以發(fā)現(xiàn)其中的特點(diǎn),那就是都屬于兩個(gè)類別之間的判斷。邏輯回歸就是解決二分類問題的利器
會(huì)有一個(gè)正例,和一個(gè)反例
三、邏輯回歸的原理
1、邏輯回歸的輸入
線性回歸的輸出,就是邏輯回歸的輸入
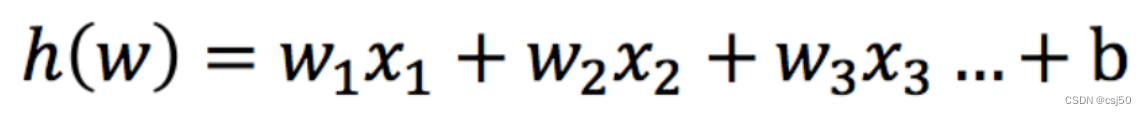
邏輯回歸的輸入就是一個(gè)線性回歸的結(jié)果
2、怎么用輸入來分類
要進(jìn)行下一步處理,帶入到sigmoid函數(shù)當(dāng)中,我們把它叫做激活函數(shù)
3、sigmoid函數(shù)
可以理解為,f(x)=1/(1+e^(-x)),1加上e的負(fù)x次方分之1
sigmoid函數(shù)又稱S型函數(shù),它是一種非線性函數(shù),可以將任意實(shí)數(shù)值映射到0-1之間的值,通常用于分類問題。它的表達(dá)式為:f(x)=1/(1+e^(-x)),其中e為自然對(duì)數(shù)的底數(shù)。它的輸出值均位于0~1之間,當(dāng)x趨向正無窮時(shí),f(x)趨向1;當(dāng)x趨向負(fù)無窮時(shí),f(x)趨向0

4、分析
將線性回歸的輸出結(jié)果,代入到x的部分
輸出結(jié)果:[0, 1]區(qū)間中的一個(gè)概率值,默認(rèn)為0.5為閾值
邏輯回歸最終的分類是通過屬于某個(gè)類別的概率值來判斷是否屬于某個(gè)類別,并且這個(gè)類別默認(rèn)標(biāo)記為1(正例),另外的一個(gè)類別會(huì)標(biāo)記為0(反例)。(方便損失計(jì)算)
5、假設(shè)函數(shù)/線性模型
1/(1 + e^(-(w1x1 + w2x2 + w3x3 + ... + wnxn +b)))
如何得出權(quán)重和偏置,使得這個(gè)模型可以準(zhǔn)確的進(jìn)行分類預(yù)測呢?
6、損失函數(shù)(真實(shí)值和預(yù)測值之間的差距)
我們可以用求線性回歸的模型參數(shù)的方法,來構(gòu)建一個(gè)損失函數(shù)
線性回歸的損失函數(shù):( - y_true)平方和/總數(shù),它是一個(gè)值
而邏輯回歸的真實(shí)值和預(yù)測值,是否屬于某個(gè)類別
所以就不能用均方誤差和最小二乘法來構(gòu)建
要使用對(duì)數(shù)似然損失
7、優(yōu)化損失(正規(guī)方程和梯度下降)
用一種優(yōu)化方法,將損失函數(shù)取得最小值,所對(duì)應(yīng)的權(quán)重值就是我們求的模型參數(shù)
四、對(duì)數(shù)似然損失
1、公式
邏輯回歸的損失,稱之為對(duì)數(shù)似然損失
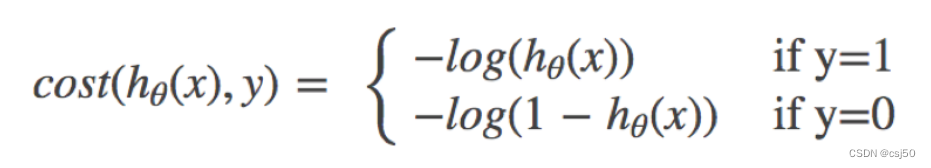
(1)它是一個(gè)分段函數(shù)
(2)如果y=1,真實(shí)值是1,屬于這個(gè)類別,損失就是 -log(y的預(yù)測值)
(3)如果y=0,真實(shí)值是0,不屬于這個(gè)類別,損失就是 -log(1-y的預(yù)測值)
2、怎么理解單個(gè)的式子呢?這個(gè)要根據(jù)log的函數(shù)圖像來理解
當(dāng)y=1時(shí):(橫坐標(biāo)是y的預(yù)測值)
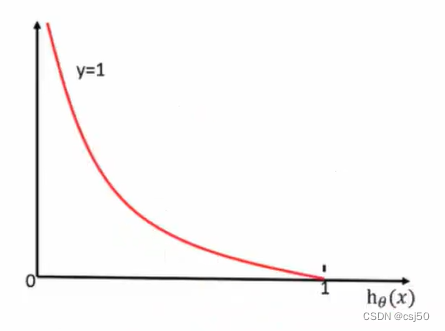
前提真實(shí)值是1,如果預(yù)測值越接近于1,則損失越接近0。如果預(yù)測值越接近于0,則損失越大
當(dāng)y=0時(shí):(橫坐標(biāo)是y的預(yù)測值)
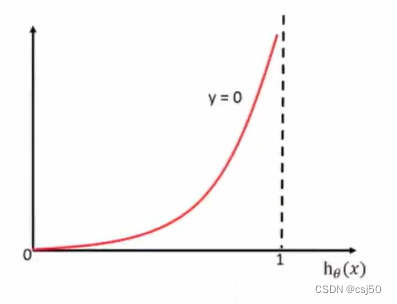
前提真實(shí)值是0,如果預(yù)測值越接近1,則損失越大
3、綜合完整損失函數(shù)
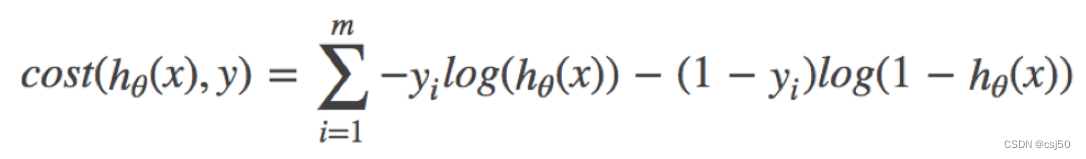
損失函數(shù):-(y真實(shí)*logy預(yù)測+(1-y真實(shí))*log(1-y預(yù)測)),求和

是線性回歸的輸出,經(jīng)過sigmoid函數(shù)映射之后的一個(gè)概率值
4、計(jì)算樣例

五、優(yōu)化損失
同樣使用梯度下降優(yōu)化算法,去減少損失函數(shù)的值。這樣去更新邏輯回歸前面對(duì)應(yīng)算法的權(quán)重參數(shù),提升原本屬于1類別的概率,降低原本是0類別的概率
六、邏輯回歸API
1、sklearn..(solver='', penalty='l2', C=1.0)
solver:優(yōu)化求解方式(默認(rèn)開源的庫實(shí)現(xiàn),內(nèi)部使用了坐標(biāo)軸下降法來迭代優(yōu)化損失函數(shù))
auto:根據(jù)數(shù)據(jù)集自動(dòng)選擇,隨機(jī)平均梯度下降
penalty:正則化的種類
C:正則化力度
2、方法相當(dāng)于(loss="log", penalty=" ")
是一個(gè)分類器
實(shí)現(xiàn)了一個(gè)普通的隨機(jī)梯度下降學(xué)習(xí),也支持平均隨機(jī)梯度下降法(ASGD),可以通過設(shè)置average=True
而使用它的優(yōu)化器已經(jīng)可以使用SAG
七、案例:癌癥分類預(yù)測-良 / 惡性乳腺癌腫瘤預(yù)測
1、數(shù)據(jù)集
數(shù)據(jù):
數(shù)據(jù)的描述:
2、數(shù)據(jù)的描述
# Attribute Domain
-- -----------------------------------------
1. Sample code number id number
2. Clump Thickness 1 - 10
3. Uniformity of Cell Size 1 - 10
4. Uniformity of Cell Shape 1 - 10
5. Marginal Adhesion 1 - 10
6. Single Epithelial Cell Size 1 - 10
7. Bare Nuclei 1 - 10
8. Bland Chromatin 1 - 10
9. Normal Nucleoli 1 - 10
10. Mitoses 1 - 10
11. Class: (2 for benign, 4 for malignant)第一列:樣本的編號(hào)
第二到十列:特征
第十一列:分類(2代表良性,4代表惡性)
3、流程分析
(1)獲取數(shù)據(jù)
讀取的時(shí)候加上names
(2)數(shù)據(jù)處理
處理缺失值
(3)數(shù)據(jù)集劃分
(4)特征工程
無量綱化處理—標(biāo)準(zhǔn)化
(5)邏輯回歸預(yù)估器
(6)模型評(píng)估
4、代碼
import pandas as pd
import numpy as np
# 1、讀取數(shù)據(jù)
column_name = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv("breast-cancer-wisconsin/breast-cancer-wisconsin.data", names=column_name)

data
# 2、缺失值處理
# 1)?替換為np.nan
data = data.replace(to_replace="?", value=np.nan)
# 2)刪除缺失樣本
data.dropna(inplace=True)
data
# 不存在缺失值
data.isnull().any()
# 3、劃分?jǐn)?shù)據(jù)集
from sklearn.model_selection import train_test_split
# 篩選特征值和目標(biāo)值
x = data.iloc[:, 1:-1] # 行都要,列從1到-1
y = data["Class"]
x.head()
y.head()
x_train, x_test, y_train, y_test = train_test_split(x, y)
# 4、標(biāo)準(zhǔn)化
from sklearn.preprocessing import StandardScaler
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
x_train
from sklearn.linear_model import LogisticRegression
# 5、預(yù)估器流程
estimator = LogisticRegression()
estimator.fit(x_train, y_train)
# 邏輯回歸的模型參數(shù):回歸系數(shù)和偏置
# 有幾個(gè)特征,就有幾個(gè)回歸系數(shù)
estimator.coef_
estimator.intercept_
# 6、模型評(píng)估
# 方法1:直接比對(duì)真實(shí)值和預(yù)測值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比對(duì)真實(shí)值和預(yù)測值:\n", y_test == y_predict)
# 方法2:計(jì)算準(zhǔn)確率
score = estimator.score(x_test, y_test)
print("準(zhǔn)確率為:\n", score)
5、運(yùn)行結(jié)果

*請認(rèn)真填寫需求信息,我們會(huì)在24小時(shí)內(nèi)與您取得聯(lián)系。
