整合營銷服務商
電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:

電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:
目錄
1.作者介紹
高志翔,男,西安工程大學電子信息學院,2021級研究生
研究方向:機器視覺與人工智能
電子郵件:
劉帥波,男,西安工程大學電子信息學院,2021級研究生,張宏偉人工智能課題組
研究方向:機器視覺與人工智能
電子郵件:
2.基于百度API的普通話識別 2.1語音識別
語音識別,就是將一段語音信號轉換成相對應的文本信息,系統主要包含特征提取、聲學模型,語言模型以及字典與解碼四大部分,此外為了更有效地提取特征往往還需要對所采集到的聲音信號進行濾波、分幀等音頻數據預處理工作,將需要分析的音頻信號從原始信號中合適地提取出來。
一般流程:
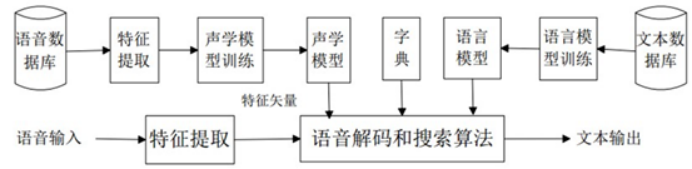
2.2百度API調用方法
通過在百度智能開發平臺,建立語音技術等應用,會獲取相對技術權限功能。
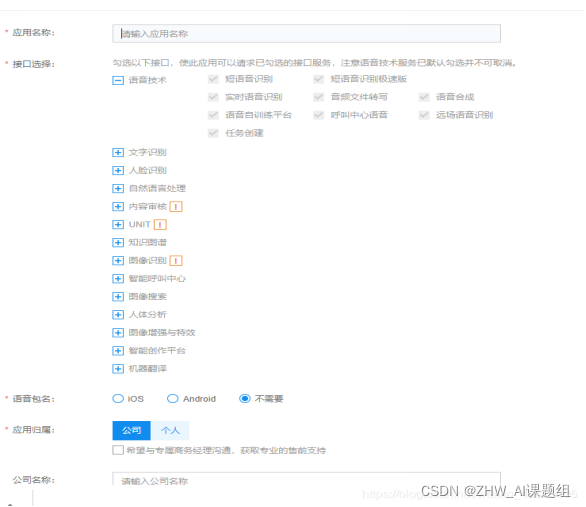
創建完畢后百度會給你一個應用列表,使用這里的AppID,API Key及Secret Key便可以進行API的調用。
3.實驗 3.1實驗準備
本次實驗我們采用的是百度API進行識別,故需要安裝baidu-aip模塊
首先打開命令行,在里面輸入pip install baidu-aip。
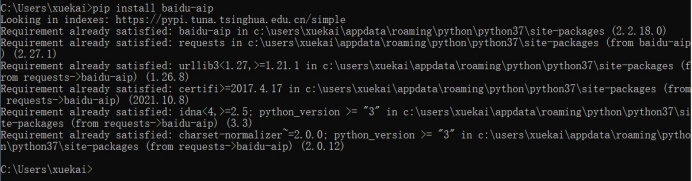
如上圖,即是安裝成功。
因為本項目采用pyqt5進行了界面編寫,故還需要安裝pyqt5模塊。
打開命令行,在里面輸入pip install pyqt5即可安裝。
接下來需要去百度AI的官網去創建應用,獲取AppID,APIKey,Secret Key。
3.2實驗結果
在此就可直接輸入對應的數字,enter鍵后便開始錄音,隨即彈出百度搜索界面,可直接進行搜索,即實驗成功!
4.實驗代碼
import wave
import requests
import time
import base64
from pyaudio import PyAudio, paInt16
import webbrowser
framerate = 16000 # 采樣率
num_samples = 2000 # 采樣點
channels = 1 # 聲道
sampwidth = 2 # 采樣寬度2bytes
FILEPATH = 'speech.wav'
base_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s"
APIKey = "********" # 填寫自己的APIKey
SecretKey = "**********" # 填寫自己的SecretKey
HOST = base_url % (APIKey, SecretKey)
def getToken(host):
res = requests.post(host)
return res.json()['access_token']
def save_wave_file(filepath, data):
wf = wave.open(filepath, 'wb')
wf.setnchannels(channels)
wf.setsampwidth(sampwidth)
wf.setframerate(framerate)
wf.writeframes(b''.join(data))
wf.close()
def my_record():
pa = PyAudio()
stream = pa.open(format=paInt16, channels=channels,
rate=framerate, input=True, frames_per_buffer=num_samples)
my_buf = []
# count = 0
t = time.time()
print('正在錄音...')
while time.time() < t + 4: # 秒
string_audio_data = stream.read(num_samples)
my_buf.append(string_audio_data)
print('錄音結束.')
save_wave_file(FILEPATH, my_buf)
stream.close()
def get_audio(file):
with open(file, 'rb') as f:
data = f.read()
return data
def speech2text(speech_data, token, dev_pid=1537):
FORMAT = 'wav'
RATE = '16000'
CHANNEL = 1
CUID = '*******'
SPEECH = base64.b64encode(speech_data).decode('utf-8')
data = {
'format': FORMAT,
'rate': RATE,
'channel': CHANNEL,
'cuid': CUID,
'len': len(speech_data),
'speech': SPEECH,
'token': token,
'dev_pid': dev_pid
}
url = 'https://vop.baidu.com/server_api'
headers = {'Content-Type': 'application/json'}
# r=requests.post(url,data=json.dumps(data),headers=headers)
print('正在識別...')
r = requests.post(url, json=data, headers=headers)
Result = r.json()
if 'result' in Result:
return Result['result'][0]
else:
return Result
def openbrowser(text):
maps = {
'百度': ['百度', 'baidu'],
'騰訊': ['騰訊', 'tengxun'],
'網易': ['網易', 'wangyi']
}
if text in maps['百度']:
webbrowser.open_new_tab('https://www.baidu.com')
elif text in maps['騰訊']:
webbrowser.open_new_tab('https://www.qq.com')
elif text in maps['網易']:
webbrowser.open_new_tab('https://www.163.com/')
else:
webbrowser.open_new_tab('https://www.baidu.com/s?wd=%s' % text)
if __name__ == '__main__':
flag = 'y'
while flag.lower() == 'y':
print('請輸入數字選擇語言:')
devpid = input('1536:普通話(簡單英文),1537:普通話(有標點),1737:英語,1637:粵語,1837:四川話\n')
my_record()
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
result = speech2text(speech, TOKEN, int(devpid))
print(result)
if type(result) == str:
openbrowser(result.strip(','))
flag = input('Continue?(y/n):')
*請認真填寫需求信息,我們會在24小時內與您取得聯系。
