整合營銷服務商
電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:

電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:
什么是灰色關聯分析
灰色關聯分析是指對一個系統發展變化態勢的定量描述和比較的方法,其基本思想是通過確定參考數據列和若干個比較數據列的幾何形狀相似程度來判斷其聯系是否緊密,它反映了曲線間的關聯程度。
通常可以運用此方法來分析各個因素對于結果的影響程度,也可以運用此方法解決隨時間變化的綜合評價類問題,其核心是按照一定規則確立隨時間變化的母序列,把各個評估對象隨時間的變化作為子序列,求各個子序列與母序列的相關程度,依照相關性大小得出結論。
灰色關聯分析的步驟
灰色關聯分析的具體計算步驟如下:
第一步:
確定分析數列。
確定反映系統行為特征的參考數列和影響系統行為的比較數列。反映系統行為特征的數據序列,稱為參考數列。影響系統行為的因素組成的數據序列,稱比較數列。
第二步,
變量的無量綱化
由于系統中各因素列中的數據可能因量綱不同,不便于比較或在比較時難以得到正確的結論。因此在進行灰色關聯度分析時,一般都要進行數據的無量綱化處理。主要有一下兩種方法
其中 k 對應時間段, i i i 對應比較數列中的一行(即一個特征)
第三步,
計算關聯系數
第四步,
計算關聯度
因為關聯系數是比較數列與參考數列在各個時刻(即曲線中的各點)的關聯程度值,所以它的數不止一個,而信息過于分散不便于進行整體性比較。因此有必要將各個時刻(即曲線中的各點)的關聯系數集中為一個值,即求其平均值,作為比較數列與參考數列間關聯程度的數量表示
,
第五步,
關聯度排序
灰色關聯分析的實例
下表為某地區國內生產總值的統計數據(以百萬元計),問該地區從2000年到2005年之間哪一種產業對GDP總量影響最大。
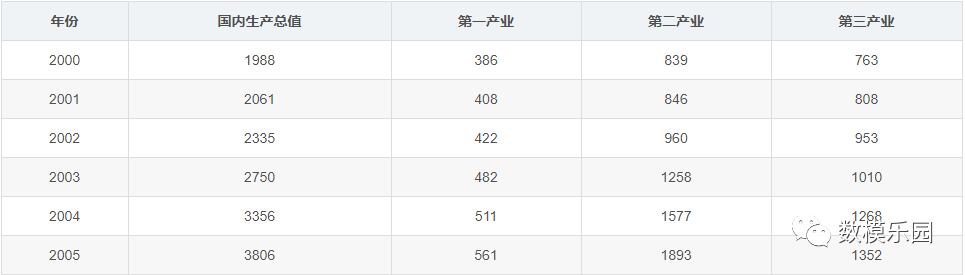
步驟1:
確立母序列
在此需要分別將三種產業與國內生產總值比較計算其關聯程度,故母序列為國內生產總值。若是解決綜合評價問題時則母序列可能需要自己生成,通常選定每個指標或時間段中所有子序列中的最佳值組成的新序列為母序列。
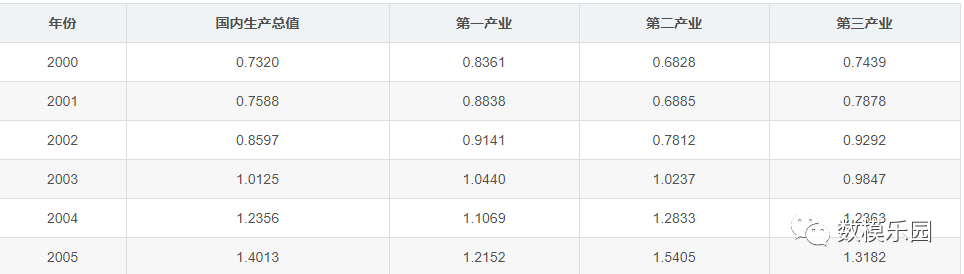
步驟2:無量綱化處理

在此采用均值化法,即將各個序列每年的統計值與整條序列的均值作比值,可以得到如下結果:
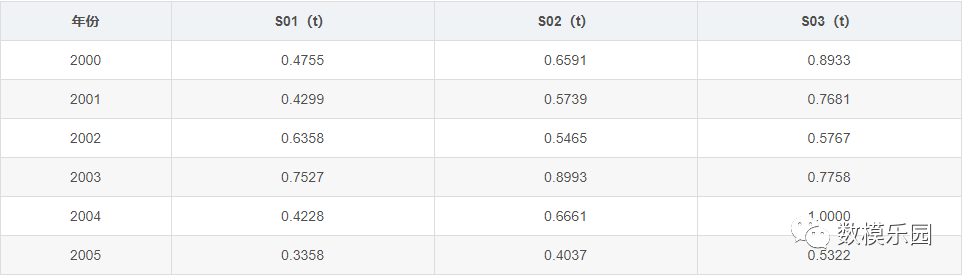
步驟3:
計算每個子序列中各項參數與母序列對應參數的關聯系數
步驟4:
計算關聯度
灰色關聯分析matlab的實現
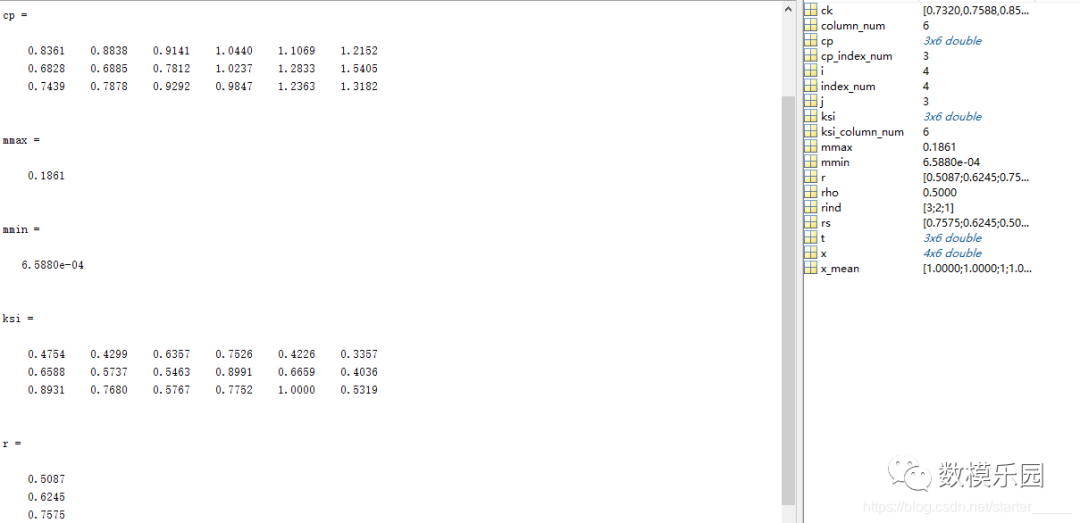
clc;
close;
clear all;
x=xlsread('data.xlsx');
x=x(:,2:end)';
=size(x,2);
=size(x,1);
% 1、數據均值化處理
x_mean=mean(x,2);
for i = 1:
x(i,:) = x(i,:)/x_mean(i,1);
end
% 2、提取參考隊列和比較隊列
ck=x(1,:)
cp=x(2:end,:)
=size(cp,1);
%比較隊列與參考隊列相減
for j = 1:
t(j,:)=cp(j,:)-ck;
end
%求最大差和最小差
mmax=max(max(abs(t)))
mmin=min(min(abs(t)))
rho=0.5;
%3、求關聯系數
ksi=((mmin+rho*mmax)./(abs(t)+rho*mmax))
%4、求關聯度
=size(ksi,2);
r=sum(ksi,2)/;
%5、關聯度排序,得到結果r3>r2>r1
[rs,rind]=sort(r,'descend');
運行結果:
灰色關聯分析python的實現
import pandas as pd
x=pd.('data.xlsx')
x=x.iloc[:,1:].T
# 1、數據均值化處理
x_mean=x.mean(axis=1)
for i in range(x.index.size):
x.iloc[i,:] = x.iloc[i,:]/x_mean[i]
# 2、提取參考隊列和比較隊列
ck=x.iloc[0,:]
cp=x.iloc[1:,:]
# 比較隊列與參考隊列相減
t=pd.()
for j in range(cp.index.size):
temp=pd.Series(cp.iloc[j,:]-ck)
t=t.append(temp,=True)
#求最大差和最小差
mmax=t.abs().max().max()
mmin=t.abs().min().min()
rho=0.5
#3、求關聯系數
ksi=((mmin+rho*mmax)/(abs(t)+rho*mmax))
#4、求關聯度
r=ksi.sum(axis=1)/ksi.columns.size
#5、關聯度排序,得到結果r3>r2>r1
result=r.(=False)
感謝數模樂園提供相關干貨

原來 8 張圖,就可以搞懂「零拷貝」了

作者 | 小林coding
來源 | 小林coding(ID:)
頭圖 | CSDN 下載自視覺中國
前言
磁盤可以說是計算機系統最慢的硬件之一,讀寫速度相差內存 10 倍以上,所以針對優化磁盤的技術非常的多,比如零拷貝、直接 I/O、異步 I/O 等等,這些優化的目的就是為了提高系統的吞吐量,另外操作系統內核中的磁盤高速緩存區,可以有效的減少磁盤的訪問次數。
這次,我們就以「文件傳輸」作為切入點,來分析 I/O 工作方式,以及如何優化傳輸文件的性能。
為什么要有 DMA 技術?
在沒有 DMA 技術前,I/O 的過程是這樣的:
為了方便你理解,我畫了一副圖:
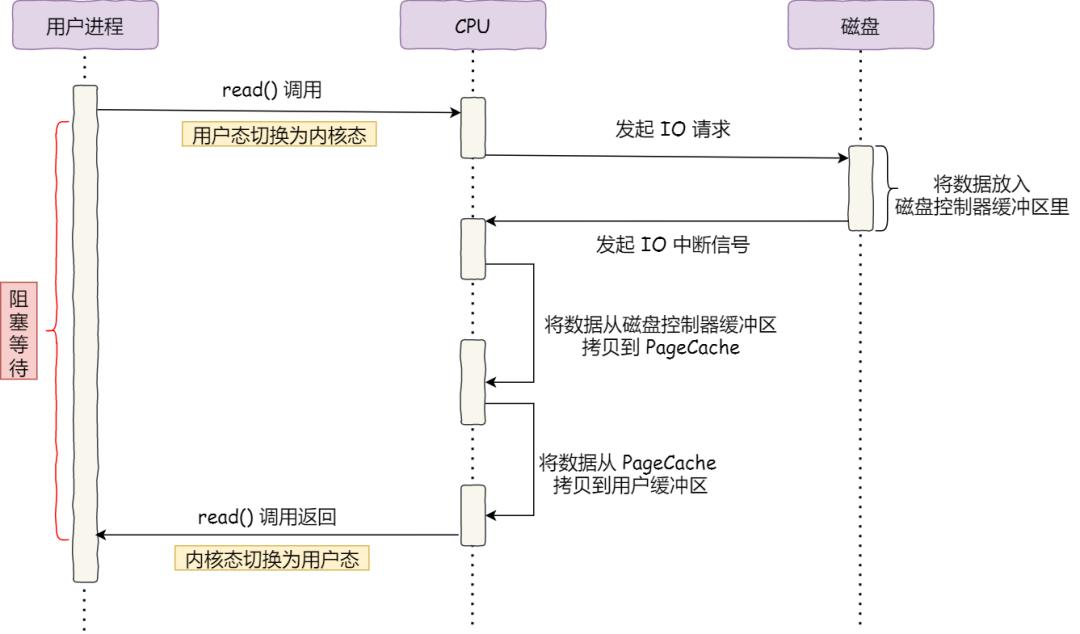
可以看到,整個數據的傳輸過程,都要需要 CPU 親自參與搬運數據的過程,而且這個過程,CPU 是不能做其他事情的。
簡單的搬運幾個字符數據那沒問題,但是如果我們用千兆網卡或者硬盤傳輸大量數據的時候,都用 CPU 來搬運的話,肯定忙不過來。
計算機科學家們發現了事情的嚴重性后,于是就發明了 DMA 技術,也就是直接內存訪問(Direct Memory Access) 技術。
什么是 DMA 技術?簡單理解就是,在進行 I/O 設備和內存的數據傳輸的時候,數據搬運的工作全部交給 DMA 控制器,而 CPU 不再參與任何與數據搬運相關的事情,這樣 CPU 就可以去處理別的事務。
那使用 DMA 控制器進行數據傳輸的過程究竟是什么樣的呢?下面我們來具體看看。
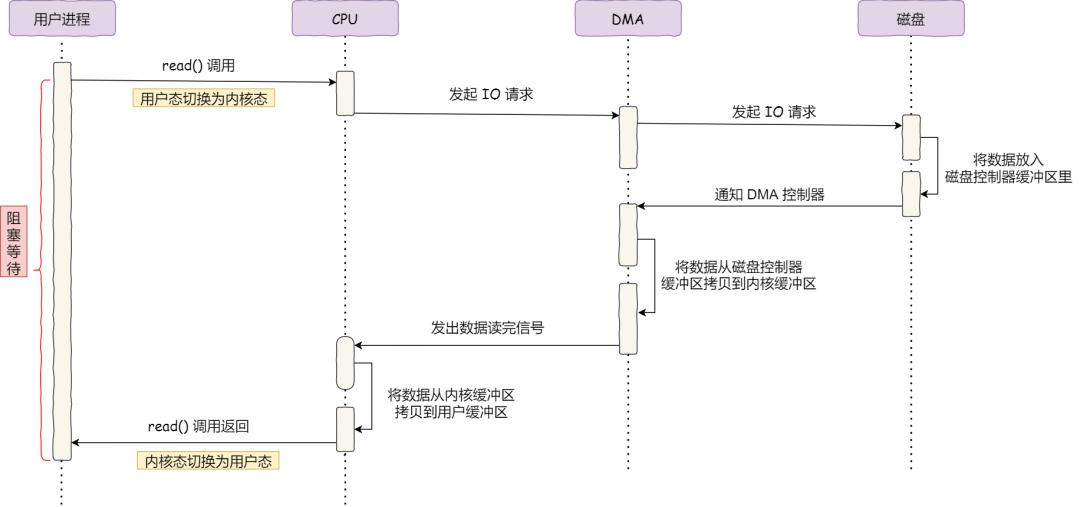
具體過程:
可以看到, 整個數據傳輸的過程,CPU 不再參與數據搬運的工作,而是全程由 DMA 完成,但是 CPU 在這個過程中也是必不可少的,因為傳輸什么數據,從哪里傳輸到哪里,都需要 CPU 來告訴 DMA 控制器。
早期 DMA 只存在在主板上,如今由于 I/O 設備越來越多,數據傳輸的需求也不盡相同,所以每個 I/O 設備里面都有自己的 DMA 控制器。
傳統的文件傳輸有多糟糕?
如果服務端要提供文件傳輸的功能,我們能想到的最簡單的方式是:將磁盤上的文件讀取出來,然后通過網絡協議發送給客戶端。
傳統 I/O 的工作方式是,數據讀取和寫入是從用戶空間到內核空間來回復制,而內核空間的數據是通過操作系統層面的 I/O 接口從磁盤讀取或寫入。
代碼通常如下,一般會需要兩個系統調用:
read(file, tmp_buf, len);write(socket, tmp_buf, len);
代碼很簡單,雖然就兩行代碼,但是這里面發生了不少的事情。
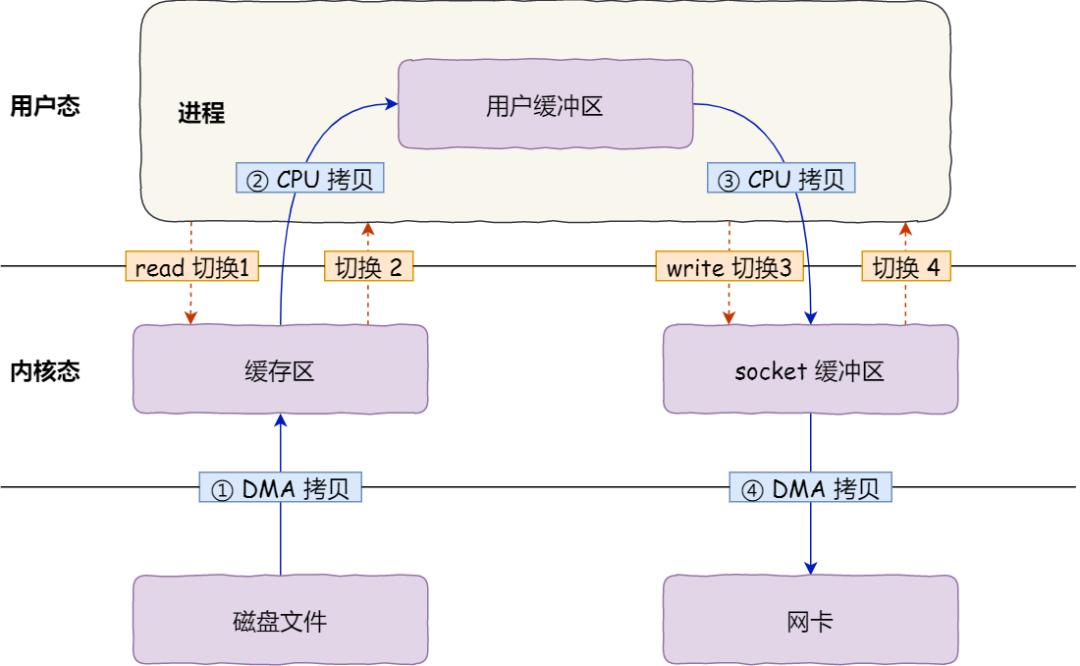
首先,期間共發生了 4 次用戶態與內核態的上下文切換,因為發生了兩次系統調用,一次是read ,一次是 write,每次系統調用都得先從用戶態切換到內核態,等內核完成任務后,再從內核態切換回用戶態。
上下文切換到成本并不小,一次切換需要耗時幾十納秒到幾微秒,雖然時間看上去很短,但是在高并發的場景下,這類時間容易被累積和放大,從而影響系統的性能。
其次,還發生了 4 次數據拷貝,其中兩次是 DMA 的拷貝,另外兩次則是通過 CPU 拷貝的,下面說一下這個過程:
我們回過頭看這個文件傳輸的過程,我們只是搬運一份數據,結果卻搬運了 4 次,過多的數據拷貝無疑會消耗 CPU 資源,大大降低了系統性能。
這種簡單又傳統的文件傳輸方式,存在冗余的上文切換和數據拷貝,在高并發系統里是非常糟糕的,多了很多不必要的開銷,會嚴重影響系統性能。
所以,要想提高文件傳輸的性能,就需要減少「用戶態與內核態的上下文切換」和「內存拷貝」的次數。
如何優化文件傳輸的性能?
先來看看,如何減少「用戶態與內核態的上下文切換」的次數呢?
讀取磁盤數據的時候,之所以要發生上下文切換,這是因為用戶空間沒有權限操作磁盤或網卡,內核的權限最高,這些操作設備的過程都需要交由操作系統內核來完成,所以一般要通過內核去完成某些任務的時候,就需要使用操作系統提供的系統調用函數。
而一次系統調用必然會發生 2 次上下文切換:首先從用戶態切換到內核態,當內核執行完任務后,再切換回用戶態交由進程代碼執行。
所以,要想減少上下文切換到次數,就要減少系統調用的次數。
再來看看,如何減少「數據拷貝」的次數?

在前面我們知道了,傳統的文件傳輸方式會歷經 4 次數據拷貝,而且這里面,「從內核的讀緩沖區拷貝到用戶的緩沖區里,再從用戶的緩沖區里拷貝到 socket 的緩沖區里」,這個過程是沒有必要的。
因為文件傳輸的應用場景中,在用戶空間我們并不會對數據「再加工」,所以數據實際上可以不用搬運到用戶空間,因此用戶的緩沖區是沒有必要存在的。
如何實現零拷貝?
零拷貝技術實現的方式通常有 2 種:
下面就談一談,它們是如何減少「上下文切換」和「數據拷貝」的次數。
mmap + write
在前面我們知道,read系統調用的過程中會把內核緩沖區的數據拷貝到用戶的緩沖區里,于是為了減少這一步開銷,我們可以用 mmap 替換 read 系統調用函數。
buf = mmap(file, len);write(sockfd, buf, len);
mmap 系統調用函數會直接把內核緩沖區里的數據「映射」到用戶空間,這樣,操作系統內核與用戶空間就不需要再進行任何的數據拷貝操作。
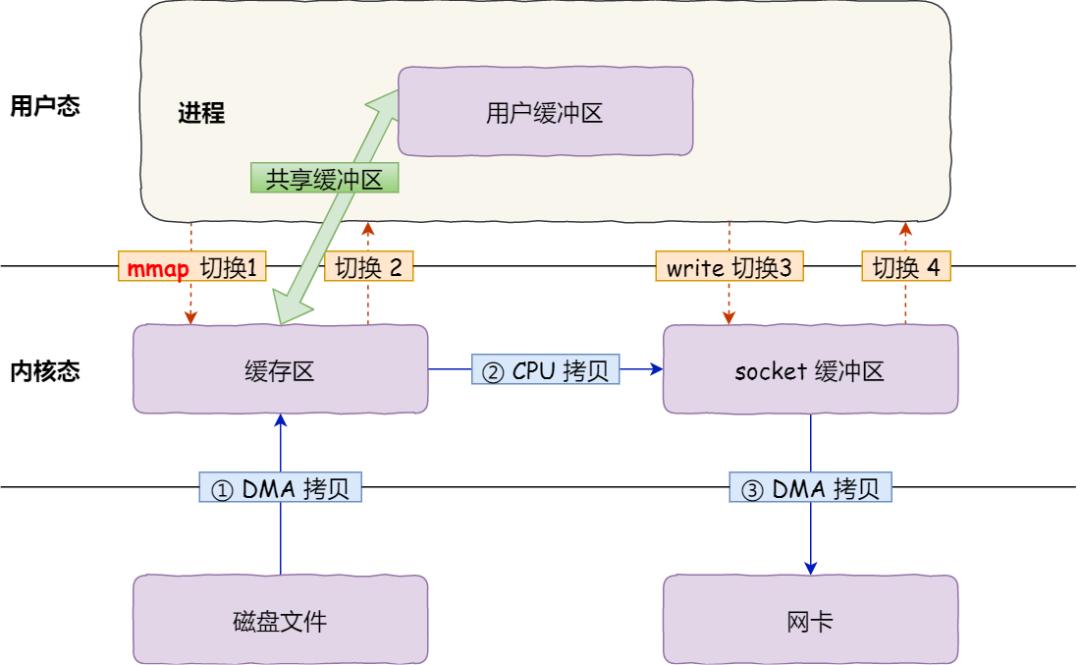
具體過程如下:
我們可以得知,通過使用 mmap 來代替read, 可以減少一次數據拷貝的過程。
但這還不是最理想的零拷貝,因為仍然需要通過 CPU 把內核緩沖區的數據拷貝到 socket 緩沖區里,而且仍然需要 4 次上下文切換,因為系統調用還是 2 次。
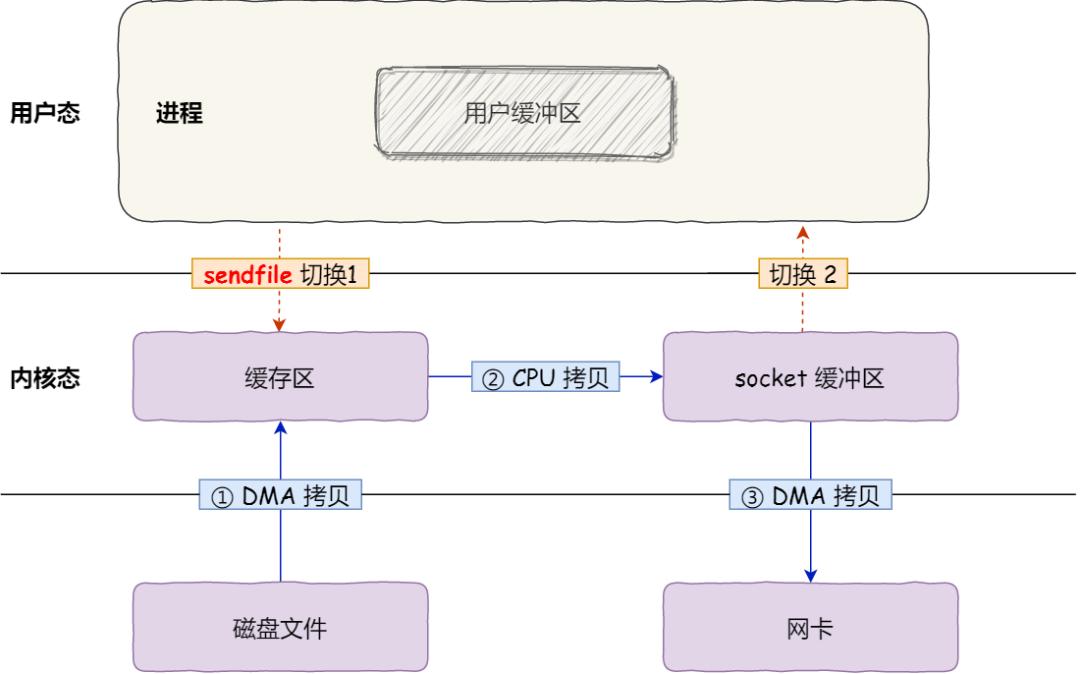
在 Linux 內核版本 2.1 中,提供了一個專門發送文件的系統調用函數 ,函數形式如下:
#includessize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
它的前兩個參數分別是目的端和源端的文件描述符,后面兩個參數是源端的偏移量和復制數據的長度,返回值是實際復制數據的長度。
首先,它可以替代前面的 read和write這兩個系統調用,這樣就可以減少一次系統調用,也就減少了 2 次上下文切換的開銷。
其次,該系統調用,可以直接把內核緩沖區里的數據拷貝到 socket 緩沖區里,不再拷貝到用戶態,這樣就只有 2 次上下文切換,和 3 次數據拷貝。如下圖:
但是這還不是真正的零拷貝技術,如果網卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技術(和普通的 DMA 有所不同),我們可以進一步減少通過 CPU 把內核緩沖區里的數據拷貝到 socket 緩沖區的過程。
你可以在你的 Linux 系統通過下面這個命令,查看網卡是否支持 scatter-gather 特性:
$ ethtool -k eth0 | grep scatter-gatherscatter-gather: on
于是,從 Linux 內核 2.4版本開始起,對于支持網卡支持 SG-DMA 技術的情況下, 系統調用的過程發生了點變化,具體過程如下:
所以,這個過程之中,只進行了 2 次數據拷貝,如下圖:
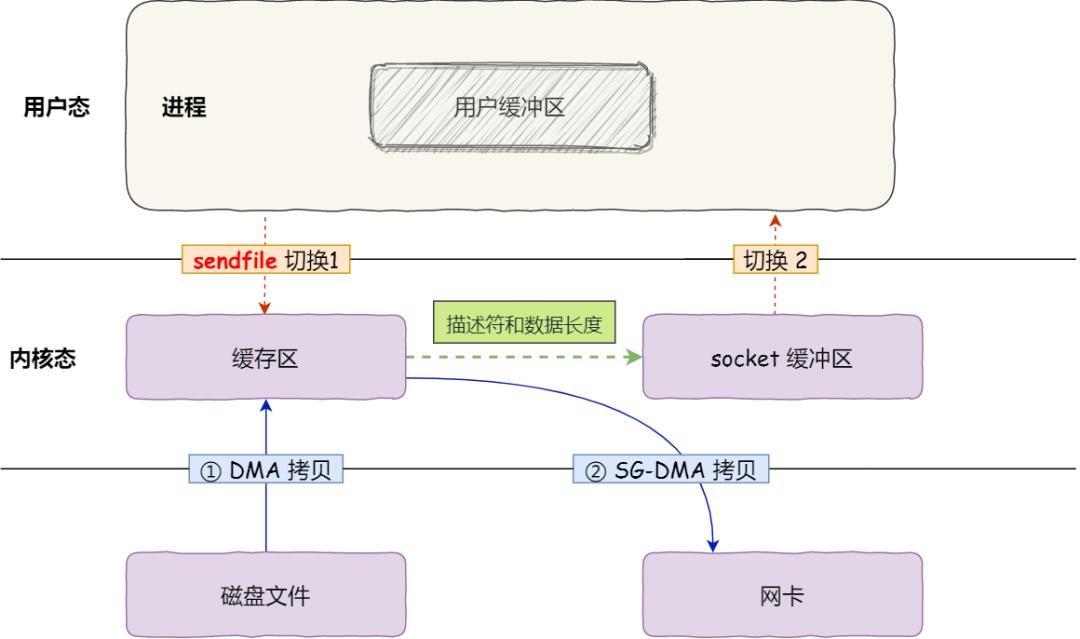
這就是所謂的零拷貝(Zero-copy)技術,因為我們沒有在內存層面去拷貝數據,也就是說全程沒有通過 CPU 來搬運數據,所有的數據都是通過 DMA 來進行傳輸的。
零拷貝技術的文件傳輸方式相比傳統文件傳輸的方式,減少了 2 次上下文切換和數據拷貝次數,只需要 2 次上下文切換和數據拷貝次數,就可以完成文件的傳輸,而且 2 次的數據拷貝過程,都不需要通過 CPU,2 次都是由 DMA 來搬運。
所以,總體來看,零拷貝技術可以把文件傳輸的性能提高至少一倍以上。
使用零拷貝技術的項目
事實上,Kafka 這個開源項目,就利用了「零拷貝」技術,從而大幅提升了 I/O 的吞吐率,這也是 Kafka 在處理海量數據為什么這么快的原因之一。
如果你追溯 Kafka 文件傳輸的代碼,你會發現,最終它調用了 Java NIO 庫里的 方法:
@Overridepubliclong transferFrom(FileChannel fileChannel, long position, long count) throws IOException {return fileChannel.transferTo(position, count, socketChannel);}
如果 Linux 系統支持 系統調用,那么 實際上最后就會使用到 系統調用函數。
曾經有大佬專門寫過程序測試過,在同樣的硬件條件下,傳統文件傳輸和零拷拷貝文件傳輸的性能差異,你可以看到下面這張測試數據圖,使用了零拷貝能夠縮短 65% 的時間,大幅度提升了機器傳輸數據的吞吐量。
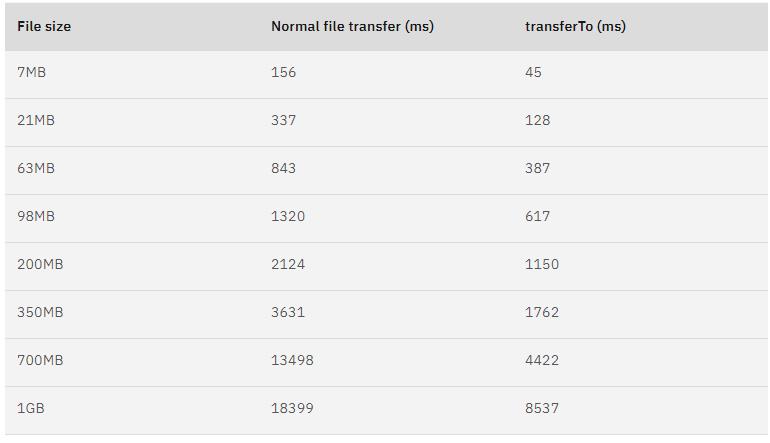
數據來源于:
另外,Nginx 也支持零拷貝技術,一般默認是開啟零拷貝技術,這樣有利于提高文件傳輸的效率,是否開啟零拷貝技術的配置如下:
http {...sendfile on...}
配置的具體意思:
當然,要使用 ,Linux 內核版本必須要 2.1 以上的版本。
有什么作用?
回顧前面說道文件傳輸過程,其中第一步都是先需要先把磁盤文件數據拷貝「內核緩沖區」里,這個「內核緩沖區」實際上是磁盤高速緩存()。

由于零拷貝使用了 技術,可以使得零拷貝進一步提升了性能,我們接下來看看 是如何做到這一點的。
讀寫磁盤相比讀寫內存的速度慢太多了,所以我們應該想辦法把「讀寫磁盤」替換成「讀寫內存」。于是,我們會通過 DMA 把磁盤里的數據搬運到內存里,這樣就可以用讀內存替換讀磁盤。
但是,內存空間遠比磁盤要小,內存注定只能拷貝磁盤里的一小部分數據。
那問題來了,選擇哪些磁盤數據拷貝到內存呢?
我們都知道程序運行的時候,具有「局部性」,所以通常,剛被訪問的數據在短時間內再次被訪問的概率很高,于是我們可以用 來緩存最近被訪問的數據,當空間不足時淘汰最久未被訪問的緩存。
所以,讀磁盤數據的時候,優先在 找,如果數據存在則可以直接返回;如果沒有,則從磁盤中讀取,然后緩存 中。
還有一點,讀取磁盤數據的時候,需要找到數據所在的位置,但是對于機械磁盤來說,就是通過磁頭旋轉到數據所在的扇區,再開始「順序」讀取數據,但是旋轉磁頭這個物理動作是非常耗時的,為了降低它的影響, 使用了「預讀功能」。
比如,假設 read 方法每次只會讀 32 KB的字節,雖然 read 剛開始只會讀 0 ~ 32 KB 的字節,但內核會把其后面的 32~64 KB 也讀取到 ,這樣后面讀取 32~64 KB 的成本就很低,如果在 32~64 KB 淘汰出 前,進程讀取到它了,收益就非常大。
所以, 的優點主要是兩個:
這兩個做法,將大大提高讀寫磁盤的性能。
但是,在傳輸大文件(GB 級別的文件)的時候, 會不起作用,那就白白浪費 DMA 多做的一次數據拷貝,造成性能的降低,即使使用了 的零拷貝也會損失性能。
這是因為如果你有很多 GB 級別文件需要傳輸,每當用戶訪問這些大文件的時候,內核就會把它們載入 中,于是 空間很快被這些大文件占滿。
另外,由于文件太大,可能某些部分的文件數據被再次訪問的概率比較低,這樣就會帶來 2 個問題:
所以,針對大文件的傳輸,不應該使用 ,也就是說不應該使用零拷貝技術,因為可能由于 被大文件占據,而導致「熱點」小文件無法利用到 ,這樣在高并發的環境下,會帶來嚴重的性能問題。
大文件傳輸用什么方式實現?
那針對大文件的傳輸,我們應該使用什么方式呢?
我們先來看看最初的例子,當調用 read 方法讀取文件時,進程實際上會阻塞在 read 方法調用,因為要等待磁盤數據的返回,如下圖:
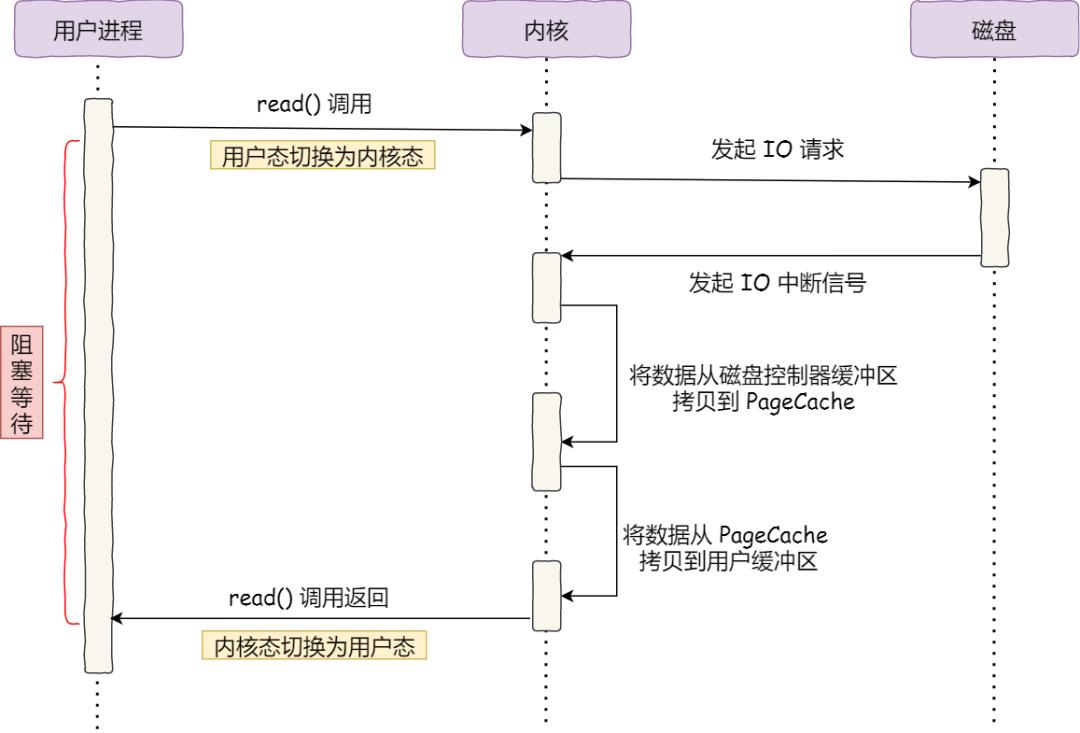
具體過程:
對于阻塞的問題,可以用異步 I/O 來解決,它工作方式如下圖:
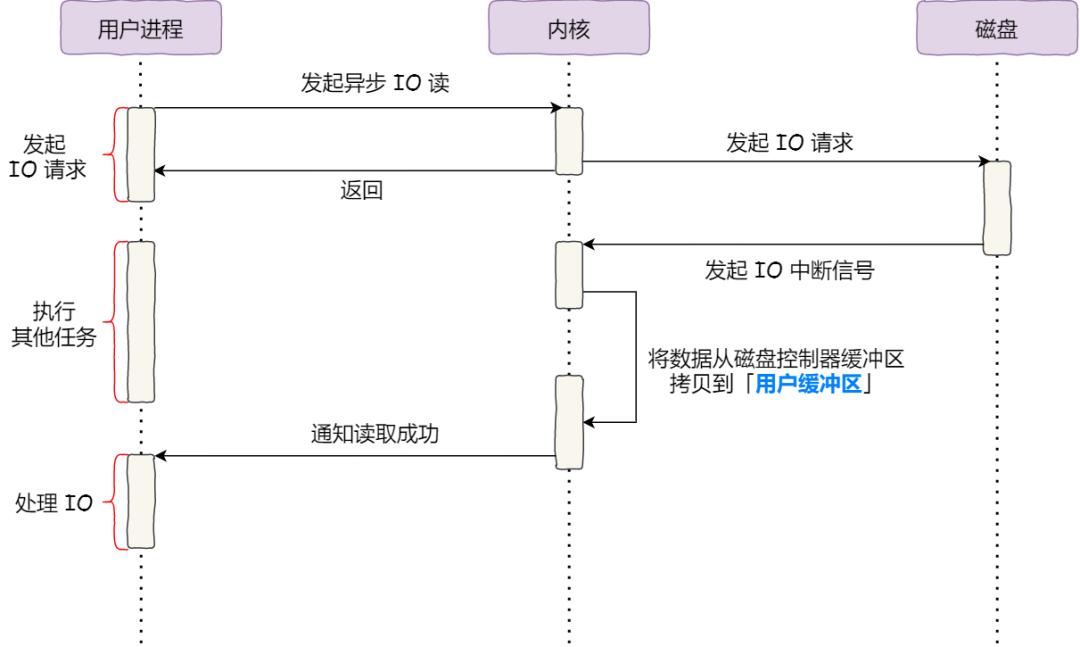
它把讀操作分為兩部分:
而且,我們可以發現,異步 I/O 并沒有涉及到 ,所以使用異步 I/O 就意味著要繞開 。
繞開 的 I/O 叫直接 I/O,使用 的 I/O 則叫緩存 I/O。通常,對于磁盤,異步 I/O 只支持直接 I/O。
前面也提到,大文件的傳輸不應該使用 ,因為可能由于 被大文件占據,而導致「熱點」小文件無法利用到 。
于是,在高并發的場景下,針對大文件的傳輸的方式,應該使用「異步 I/O + 直接 I/O」來替代零拷貝技術。
直接 I/O 應用場景常見的兩種:
另外,由于直接 I/O 繞過了 ,就無法享受內核的這兩點的優化:
于是,傳輸大文件的時候,使用「異步 I/O + 直接 I/O」了,就可以無阻塞地讀取文件了。
所以,傳輸文件的時候,我們要根據文件的大小來使用不同的方式:
在 Nginx 中,我們可以用如下配置,來根據文件的大小來使用不同的方式:
location /video/ {sendfile on;aio on;directio 1024m;}
當文件大小大于 值后,使用「異步 I/O + 直接 I/O」,否則使用「零拷貝技術」。
總結
早期 I/O 操作,內存與磁盤的數據傳輸的工作都是由 CPU 完成的,而此時 CPU 不能執行其他任務,會特別浪費 CPU 資源。
于是,為了解決這一問題,DMA 技術就出現了,每個 I/O 設備都有自己的 DMA 控制器,通過這個 DMA 控制器,CPU 只需要告訴 DMA 控制器,我們要傳輸什么數據,從哪里來,到哪里去,就可以放心離開了。后續的實際數據傳輸工作,都會由 DMA 控制器來完成,CPU 不需要參與數據傳輸的工作。
傳統 IO 的工作方式,從硬盤讀取數據,然后再通過網卡向外發送,我們需要進行 4 上下文切換,和 4 次數據拷貝,其中 2 次數據拷貝發生在內存里的緩沖區和對應的硬件設備之間,這個是由 DMA 完成,另外 2 次則發生在內核態和用戶態之間,這個數據搬移工作是由 CPU 完成的。
為了提高文件傳輸的性能,于是就出現了零拷貝技術,它通過一次系統調用( 方法)合并了磁盤讀取與網絡發送兩個操作,降低了上下文切換次數。另外,拷貝數據都是發生在內核中的,天然就降低了數據拷貝的次數。
Kafka 和 Nginx 都有實現零拷貝技術,這將大大提高文件傳輸的性能。
零拷貝技術是基于 的, 會緩存最近訪問的數據,提升了訪問緩存數據的性能,同時,為了解決機械硬盤尋址慢的問題,它還協助 I/O 調度算法實現了 IO 合并與預讀,這也是順序讀比隨機讀性能好的原因。這些優勢,進一步提升了零拷貝的性能。
需要注意的是,零拷貝技術是不允許進程對文件內容作進一步的加工的,比如壓縮數據再發送。
另外,當傳輸大文件時,不能使用零拷貝,因為可能由于 被大文件占據,而導致「熱點」小文件無法利用到 ,并且大文件的緩存命中率不高,這時就需要使用「異步 IO + 直接 IO 」的方式。
在 Nginx 里,可以通過配置,設定一個文件大小閾值,針對大文件使用異步 IO 和直接 IO,而對小文件使用零拷貝。

點分享
*請認真填寫需求信息,我們會在24小時內與您取得聯系。
