整合營銷服務商
電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:

電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:
目錄
1. MySQL事務
2. MySQL索引
3. SQL優化
4.常見問題
上次我們討論了MySQL的運行流程及原理,字段設計,存儲引擎和查詢緩存。
MySQL面試知識點追命連環問(一)
這次我們繼續來追命連環問關于事務,索引,SQL優化等相關的內容。準備好了嗎?
1. MySQL事務
面試官:你知道事務嗎?
我:知道。事務()是訪問和更新數據庫的程序執行單元;
事務中可能包含一個或多個sql語句,這些語句要么都執行,要么都不執行。
事務主要有四大特性。即ACID:原子性,一致性,隔離性和持久性。
原子性:不可分割的操作單元,事務中所有操作,要么全部成功;要么回滾到執行事務之前的狀態。
一致性:在事務開始之前和事務結束以后,數據庫的完整性約束沒有被破壞。
隔離性:事務操作之間彼此獨立和透明互不影響。如果一個事務處理后的結果,影響了其他事務,那么其他事務會撤回。
持久性:事務一旦提交,其結果就是永久的。即便發生系統故障,也能恢復。
面試官:嗯四大特性說的沒錯,那你知道高并發場景下事務可能會出現的問題嗎?
我:事務并發執行的話確實會產生一些問題。比如說:幻讀,臟讀,不可重復讀。因為隔離性臟寫是不會發生的。
臟讀:一個事務讀取到另一個未提交事務修改的數據。
session?A:查詢,得到某條數據
session B:修改某條數據,但是最后回滾掉啦
session A:在sessionB修改某條數據之后,在回滾之前,讀取了該條記錄
對于session A來說,讀到了session回滾之前的臟數據
不可重復讀:多次讀取的數據內容不一樣。
session?A:查詢某條記錄
session?B?:?修改該條記錄,并提交事務
session?A?:?再次查詢該條記錄,發現前后查詢不一致
幻讀:前后多次讀取,數據總量不一樣。
session?A:查詢表內所有記錄
session?B?:?新增一條記錄,并查詢表內所有記錄
session?A?:?再次查詢該條記錄,發現前后查詢不一致
面試管:那什么情況下會出現這些問題呢?
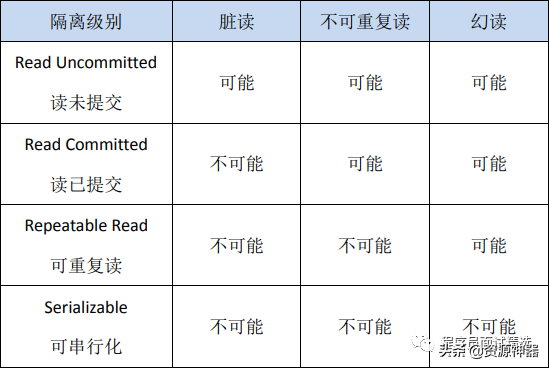
MySQL標準中定義了四種隔離級別,并規定了每種隔離級別下上述幾個問題是否存在。
一般來說,隔離級別越低,系統開銷越低,可支持的并發越高,但隔離性也越差。隔離級別與讀問題的關系如下:
?
讀未提交:臟讀,不可重復讀,幻讀都有可能發生

讀已提交:不可重復讀,幻讀可能發生
可重復讀:幻讀可能發生
可串行化:都不可能發生
在實際應用中,讀未提交在并發時會導致很多問題,而性能相對于其他隔離級別提高卻很有限,因此使用較少。
可串行化強制事務串行,并發效率很低,只有當對數據一致性要求極高且可以接受沒有并發時使用,因此使用也較少。
因此在大多數數據庫系統中,默認的隔離級別是讀已提交(如Oracle)或可重復讀。
MySQL事務默認的隔離級別是可重復讀,而且MySQL可以解決了幻讀的問題。
面試官:看來你對事務理解的還不錯。那你知道MySQL的另一個重要特性索引嗎?
2. MySQL索引
答:索引就是數據庫管理系統中一個排序的數據結構,以協助快速查詢、更新數據庫表中數據。索引的實現通常使用B樹及其變種B+樹。
在數據之外,數據庫維護這些原來快速查找的索引也是要付出代價的。一是增加了數據庫的存儲,二是在插入和修改數據時要花費較多的時間(因為索引也要隨之變動)。
面試官:那索引是怎樣實現的呢?MyISAM和Innodb的實現方式一樣嗎?
答:不一樣的。MyISAM和Innodb雖然都使用B+樹作為索引結構,但索引的實現方式還是不一樣的。
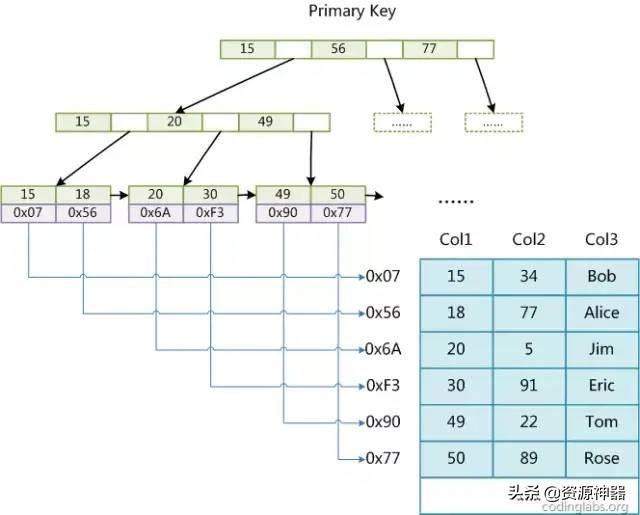
MyISAM的葉節點的data域存放的是數據記錄的地址,而Innodb數據文件本身就是索引文件。
MyISAM中索引檢索的算法為首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,則取出其data域的值,然后以data域的值為地址,讀取相應數據記錄。
?
MyISAM索引
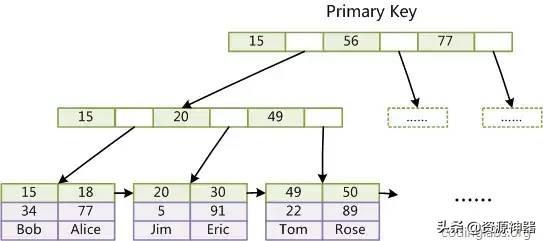
而在InnoDB中,表數據文件本身就是按B+Tree組織的一個索引結構,這棵樹的葉節點data域保存了完整的數據記錄。這個索引的key是數據表的主鍵,因此InnoDB表數據文件本身就是主索引。
?
Innodb索引
因為InnoDB的數據文件本身要按主鍵聚集,所以InnoDB要求表必須有主鍵(MyISAM可以沒有)。
如果沒有顯式指定,則MySQL系統會自動選擇一個可以唯一標識數據記錄的列作為主鍵,如果不存在這種列,則MySQL自動為InnoDB表生成一個隱含字段作為主鍵。
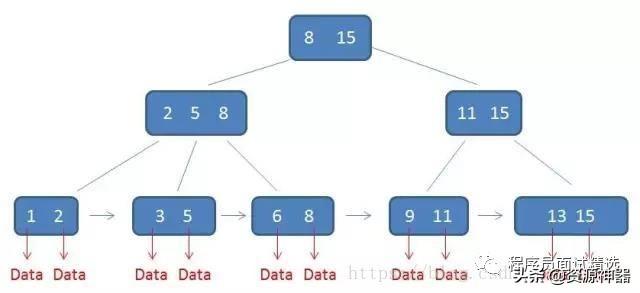
B+樹是一種B樹的變種,為有序數組鏈表+平衡多叉樹。基本和B樹類似,只有葉子節點存放數據,而且葉子節點之間通過指針相連。
面試官:那為什么索引用B+樹呢,B+樹有什么優點呢?
1、 B+樹的磁盤讀寫代價更低:B+樹的內部節點并沒有指向關鍵字具體信息的指針,因此其內部節點相對B樹更小,如果把所有同一內部節點的關鍵字存放在同一盤塊中,那么盤塊所能容納的關鍵字數量也越多,一次性讀入內存的需要查找的關鍵字也就越多,相對IO讀寫次數就降低了。
2、由于B+樹的數據都存儲在葉子結點中,分支結點均為索引,方便掃庫,只需要掃一遍葉子結點即可,但是B樹因為其分支結點同樣存儲著數據,我們要找到具體的數據,需要進行一次中序遍歷按序來掃,所以B+樹更加適合在區間查詢的情況,所以通常B+樹用于數據庫索引。
?
面試官:那什么是聚簇索引呢?
聚簇索引是一種數據存儲方式,它實際上是在同一個結構中保存了B+樹索引和數據行,InnoDB表是按照聚簇索引組織的。
InnoDB通過主鍵聚簇數據。他使用主鍵值的大小來進行記錄和頁的排序。葉子節點存儲的是完整的用戶記錄。
注:聚簇索引不需要我們顯示的創建,他是由InnoDB存儲引擎自動為我們創建的。如果沒有主鍵,其也會默認創建一個。
但聚簇索引只有在搜索條件為主鍵是才發揮作用,如果為其他的字段就不行,這個時候就需要普通索引了。
二級索引的葉子節點不再是完整的數據記錄,而是字段和主鍵值。當需要這條記錄的其他字段時仍然需要根據這個主鍵id去查詢,這個步驟叫做回表。
聚簇索引表最大限度地提高了I/O密集型應用的性能,但它也有以下幾個限制:
插入速度嚴重依賴于插入順序,按照主鍵的順序插入是最快的方式,否則將會出現頁分裂,嚴重影響性能。因此,對于InnoDB表,我們一般都會定義一個自增的ID列為主鍵。更新主鍵的代價很高,因為將會導致被更新的行移動。因此,對于InnoDB表,我們一般定義主鍵為不可更新的。二級索引訪問需要兩次索引查找,第一次找到主鍵值,第二次根據主鍵值找到行數據。
面試官:索引有哪些類型?索引越多越好嗎?
除了上面說的主鍵索引和普通索引,還有唯一索引,聯合索引和全文索引。
唯一索引:該列具有唯一性的同時又是索引,不允許重復。
全文索引:主要用于文本的查詢,它的出現是為了解決WHERE name LIKE “%word%"這類針對文本的模糊查詢效率較低的問題。
聯合索引:對多列值進行一個索引,其效率大于索引合并。需遵循前綴原則。
建索引是有開銷的所以也不是越多越好,只要在需要的字段上建立索引。
第一,創建索引和維護索引要耗費時間,這種時間隨著數據量的增加而增加。
第二,索引需要占物理空間,除了數據表占數據空間之外,每一個索引還要占一定的物理空間,如果要建立聚簇索引,那么需要的空間就會更大。
第三,當對表中的數據進行增加、刪除和修改的時候,索引也要動態的維護,這樣就降低了數據的維護速度。
索引的使用需要注意以下幾點:
1.最左前綴原則。一個聯合索引(a,b,c),如果有一個查詢條件有a,有b,那么他則走索引,如果有一個查詢條件沒有a,那么他則不走索引。
2.使用唯一索引。具有多個重復值的列,其索引效果最差。
3.不要過度索引。每個額外的索引都要占用額外的磁盤空間,并降低寫操作的性能。在修改表的內容時,索引必須進行更新,有時可能需要重構,因此,索引越多,所花的時間越長。
4、索引列不能參與計算,保持列“干凈”,比如() = ’2014-05-29’就不能使用到索引,原因很簡單,b+樹中存的都是數據表中的字段值,但進行檢索時,需要把所有元素都應用函數才能比較,顯然成本太大。所以語句應該寫成 = (’2014-05-29’);
5.一定要設置一個主鍵。前面聚簇索引說到如果不指定主鍵,InnoDB會自動為其指定主鍵,這個我們是看不見的。反正都要生成一個主鍵的,還不如我們設置,以后在某些搜索條件時還能用到主鍵的聚簇索引。
6.主鍵推薦用自增id,而不是uuid。上面的聚簇索引說到每頁數據都是排序的,并且頁之間也是排序的,如果是uuid,那么其肯定是隨機的,其可能從中間插入,導致頁的分裂,產生很多表碎片。如果是自增的,那么其有從小到大自增的,有順序,那么在插入的時候就添加到當前索引的后續位置。當一頁寫滿,就會自動開辟一個新的頁。
索引禁忌:
面試官:看來你對索引掌握的很不錯啊,那你平常遇到慢查詢是怎么優化的呢?
3. SQL優化
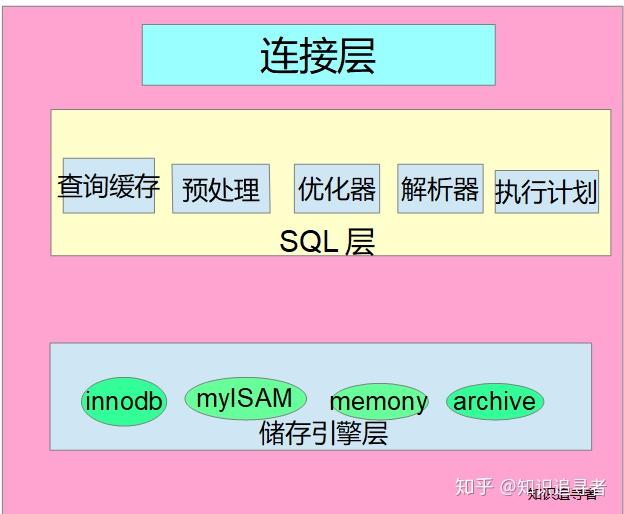
SQL語句從客戶端經由網絡協議到查詢緩存,如果沒有命中緩存,再經過解析工作,得到準確的SQL然后再來到優化器。
首先,我們知道每一條SQL都有不同的執行方法,要不通過索引,要不通過全表掃描的方式。
影響SQL速度的主要在I/O成本和CPU成本的消耗上。
數據存儲在硬盤上,我們想要進行某個操作需要將其加載到內存中,這個過程的時間被稱為I/O成本。在內存對結果集進行排序的時間被稱為CPU成本。
所以進行sql優化首先進行索引優化,讓我們的sql語句盡量走索引而不是走全表掃描的方法。
在平常遇到慢查詢時首先去分析慢查詢日志,找出慢查詢的sql。然后針對這些sql進行分析。常見慢查詢主要有以下幾種情況:
索引沒起作用。字段沒建立索引,或者是索引沒有起作用。使用了like關鍵字或使用了多列索引的查詢語句。數據庫結構不合理。合理的數據庫結構不僅可以使數據庫占用更小的磁盤,也可以讓sql執行速度更快。一可以將字段很多的表拆解成多個表。二增加中間表。分解關聯查詢。將大查詢分成多個小查詢。優化limit分頁。當偏移量非常大時會導致前面查詢到的無用數據都要舍棄掉,如果表非常大,且篩選字段沒有合適的索引,那么這樣的代價是非常高的。如我們下一次的查詢能從前一次查詢結束后標記的位置開始查找,那將節省很多開銷。4.常見問題
問題一:嗯現在我們來看看具體問題,那你看這條語句會用到索引嗎?
以下語句是否會應用索引:SELECT FROM users WHERE YEAR(adddate) < 2007;
答:不會,因為只要列涉及到運算,MySQL就不會使用索引。
問題二:那如果列值為NULL時,查詢是否會用到索引?
在MySQL里NULL值的列也是走索引的。當然,如果計劃對列進行索引,就要盡量避免把它設置為可空,MySQL難以優化引用了可空列的查詢,它會使索引、索引統計和值更加復雜。
問題三:索引一定會提高速度嗎?
通常,通過索引查詢數據比全表掃描要快。但是我們也必須注意到它的代價。
索引需要空間來存儲,也需要定期維護, 每當有記錄在表中增減或索引列被修改時,索引本身也會被修改. 這意味著每條記錄的INSERT,DELETE,UPDATE將為此多付出4,5 次的磁盤I/O. 因為索引需要額外的存儲空間和處理,那些不必要的索引反而會使查詢反應時間變慢。使用索引查詢不一定能提高查詢性能。
問題四:如何查詢第n高的工資?
SELECT DISTINCT(salary) from employee ORDER BY salary DESC LIMIT n-1,1問題五:一個6億的表a,一個3億的表b,通過外間tid關聯,你如何最快的查詢出滿足條件的第50000到第50200中的這200條數據記錄。
1、如果A表TID是自增長,并且是連續的,B表的ID為索引
select * from a,b where a.tid = b.id and a.tid>500000 limit 200;2、如果A表的TID不是連續的,那么就需要使用覆蓋索引。TID要么是主鍵,要么是輔助索引,B表ID也需要有索引。
select * from b , (select tid from a limit 50000,200) a where b.id = a .tid;好啦,今天的追命連環問就到這里了,下次繼續,如對文章有疑惑或補充的地方歡迎留言交流(●'?'●)。原創不易,如果對你有幫助的話歡迎點贊!
?
*請認真填寫需求信息,我們會在24小時內與您取得聯系。
